

Advanced Techniques for Handling Missing Data in Cybersecurity Applications
DataScience CyberSecurity - #0004

In the domain of cybersecurity, the accuracy and reliability of data are paramount. Data-driven decision-making is at the core of modern cybersecurity practices, influencing everything from threat detection to incident response. However, missing data—a common occurrence in real-world datasets can pose significant challenges, potentially compromising the effectiveness of security measures. In this article, we will explore advanced techniques for handling missing data within cybersecurity contexts, offering insights tailored to professionals seeking to enhance the robustness of their data-driven security solutions.
The Challenge of Missing Data in Cybersecurity
Missing data in cybersecurity can arise from various sources, including incomplete log entries, network packet loss, interrupted data collection processes, or even deliberate data tampering by adversaries. Understanding the nature of missing data is crucial for choosing the appropriate strategy to address it. There are three main types of missing data scenarios typically encountered in cybersecurity:
Missing Completely at Random (MCAR): The probability of data being missing is independent of both observed and unobserved data. In cybersecurity, random network failures or occasional logging errors could cause this, occurring independently of any specific event or condition.
Missing at Random (MAR): Here, the missingness is related to the observed data but not the missing data itself. For example, certain network logs might be incomplete due to high traffic volumes during peak hours, which correlates with other observed metrics like bandwidth usage or CPU load.
Missing Not at Random (MNAR): The most problematic scenario is where the missing data is directly related to the unobserved data itself. In cybersecurity, MNAR situations often result from sophisticated attacks where adversaries deliberately manipulate or hide their tracks, such as selectively deleting logs or obscuring traces of malicious activity.
Advanced Techniques for Imputing Missing Data in Cybersecurity
Addressing missing data in cybersecurity requires advanced imputation techniques that can handle the complex, high-dimensional nature of security datasets and the critical need for accurate threat detection.

Multiple Imputation (MI):
Concept: MI generates multiple datasets by imputing missing values multiple times, combining the results to account for the uncertainty in the imputations. This approach is particularly useful when dealing with MAR data, where missing entries might correlate with other observable data points, such as partial event logs during a DDoS attack.
Application in Cybersecurity: In intrusion detection systems (IDS), MI can help maintain the integrity of traffic analysis by imputing missing network packets, ensuring that anomaly detection algorithms remain effective. By reflecting the uncertainty in data, MI provides a more robust foundation for
machine learning models that drive automated threat detection.
MissForest:
Concept: MissForest uses the Random Forest algorithm to iteratively impute missing values based on observed data, handling mixed types of variables (categorical and continuous). This method is particularly well-suited for cybersecurity datasets where variables can have complex, non-linear interactions.
Application in Cybersecurity: MissForest effectively reconstructs incomplete datasets from network traffic analysis, addressing missing values caused by packet loss or intentional tampering. By modeling intricate dependencies between features, it preserves key patterns in attack behavior and enhances the accuracy of intrusion detection systems.
Multiple Imputation by Chained Equations (MICE):
Concept: MICE performs multiple imputations by modeling each variable with missing data as a function of other variables in a chained equation approach. It is particularly useful for datasets with mixed data types and multiple variables influencing each other.
Application in Cybersecurity: MICE can be utilized in scenarios like security event logs, where missing entries might correlate with other log attributes. By iteratively modeling these relationships, MICE aligns the imputed data closely with the observed data, thereby improving the reliability of event correlation and incident response mechanisms.
Bayesian Networks:
Concept: Bayesian networks use probabilistic graphical models to represent the conditional dependencies between variables. Missing data can be inferred through the posterior distribution of these variables, making it a powerful tool for scenarios where the relationships between features are well understood.
Application in Cybersecurity: In advanced threat detection, Bayesian networks can model the probabilistic relationships between different indicators of compromise (IoCs). For example, if certain log entries are missing, the network can infer these based on the observed patterns of related logs, helping to reconstruct the sequence of a cyberattack even when data is incomplete.
Deep Learning-based Imputation:
Autoencoders and GANs: Advanced deep learning models like Autoencoders and Generative Adversarial Networks (GANs) can be used for imputing missing data in cybersecurity. Autoencoders learn a compressed representation of the data, which can be used to reconstruct missing values, while GANs can generate realistic data patterns that match the observed data distribution.
Application in Cybersecurity: These models are particularly effective in scenarios involving high-dimensional data, such as network traffic analysis, where missing packets or corrupted data streams need to be reconstructed. By learning the underlying data distribution, deep learning models can generate plausible imputations that retain the characteristics of the original data, ensuring that threat detection models remain accurate.
Evaluating Imputation Strategies for Cybersecurity
Selecting the right imputation strategy is critical to maintaining the effectiveness of cybersecurity defenses. Key evaluation metrics include:
Impact on Model Performance: The imputation method should enhance or at least maintain the performance of cybersecurity models, measured by accuracy, precision, recall, and F1-score. For instance, in an IDS, effective imputation should improve the detection of malicious activity without increasing false positives.
Preservation of Data Integrity: The imputation process must preserve the original distribution and relationships within the data. Methods like MissForest and MICE excel at maintaining these properties, making them suitable for complex cybersecurity datasets where accurate modeling of feature interactions is crucial.
Computational Efficiency: In real-time cybersecurity applications, such as live threat detection, the imputation method needs to be computationally efficient. Techniques like deep learning-based imputations may require optimization to be feasible in such time-sensitive environments.
Bias and Variance Considerations: When choosing an imputation method, you should minimize the bias introduced by the imputation process while maintaining or enhancing the variance needed for accurate model predictions. Techniques like MI and Bayesian networks are designed to handle this balance effectively.
Example
Below is a Python implementation that demonstrates advanced techniques for handling missing data in cybersecurity applications. This implementation includes the generation of a synthetic cybersecurity dataset, the imputation of missing data using advanced methods, and visualizations to highlight the effects of different imputation techniques.
Step 1: We'll start by creating a synthetic dataset that simulates typical features found in network traffic data, such as packet_size, source_ip, destination_ip, protocol, and attack_type. The dataset will include missing values to simulate real-world scenarios.
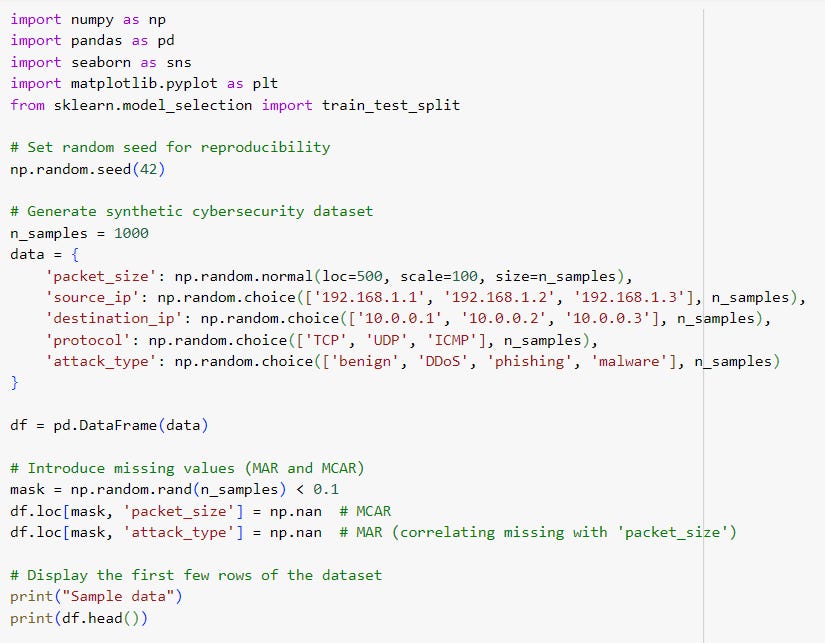
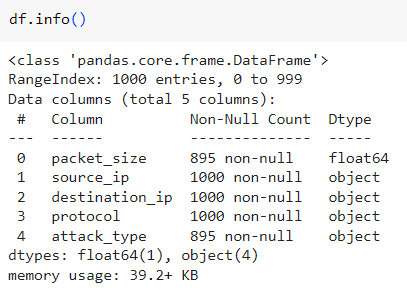
The DataFrame has 1000 entries and 5 columns, with packet_size and attack_type containing 105 missing values. The other columns (source_ip, destination_ip, protocol) are fully populated and categorized as objects.
Step 2: We'll use several advanced imputation techniques, such as Multiple Imputation by Chained Equations (MICE), MissForest, and K-Nearest Neighbors (KNN) for handling the missing data.

Step 3: We will visualize the effects of different imputation methods on the distribution of packet_size and the integrity of the categorical attack_type feature.

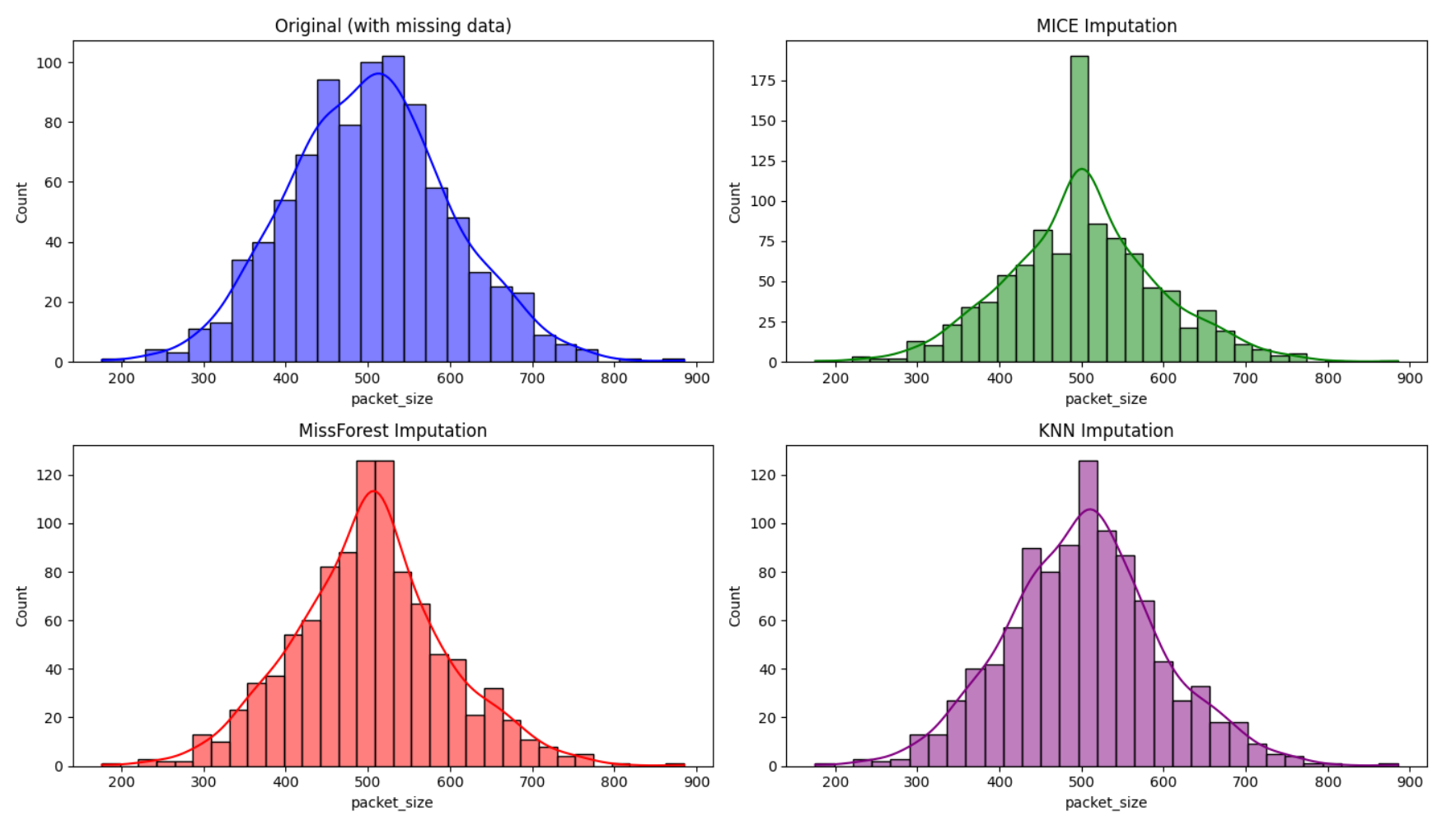
Interpretation: The above histograms show the distribution of packet_size before and after imputation using the MICE, MissForest, and KNN methods.
Original Data: Shows gaps due to missing values, leading to an irregular distribution.
MICE Imputation: Introduces a noticeable spike at the mean, resulting in a less natural distribution.
MissForest Imputation: Closely mirrors the original distribution, capturing natural variability effectively.
KNN Imputation: It also closely resembles the original data, preserving its natural shape and spread.
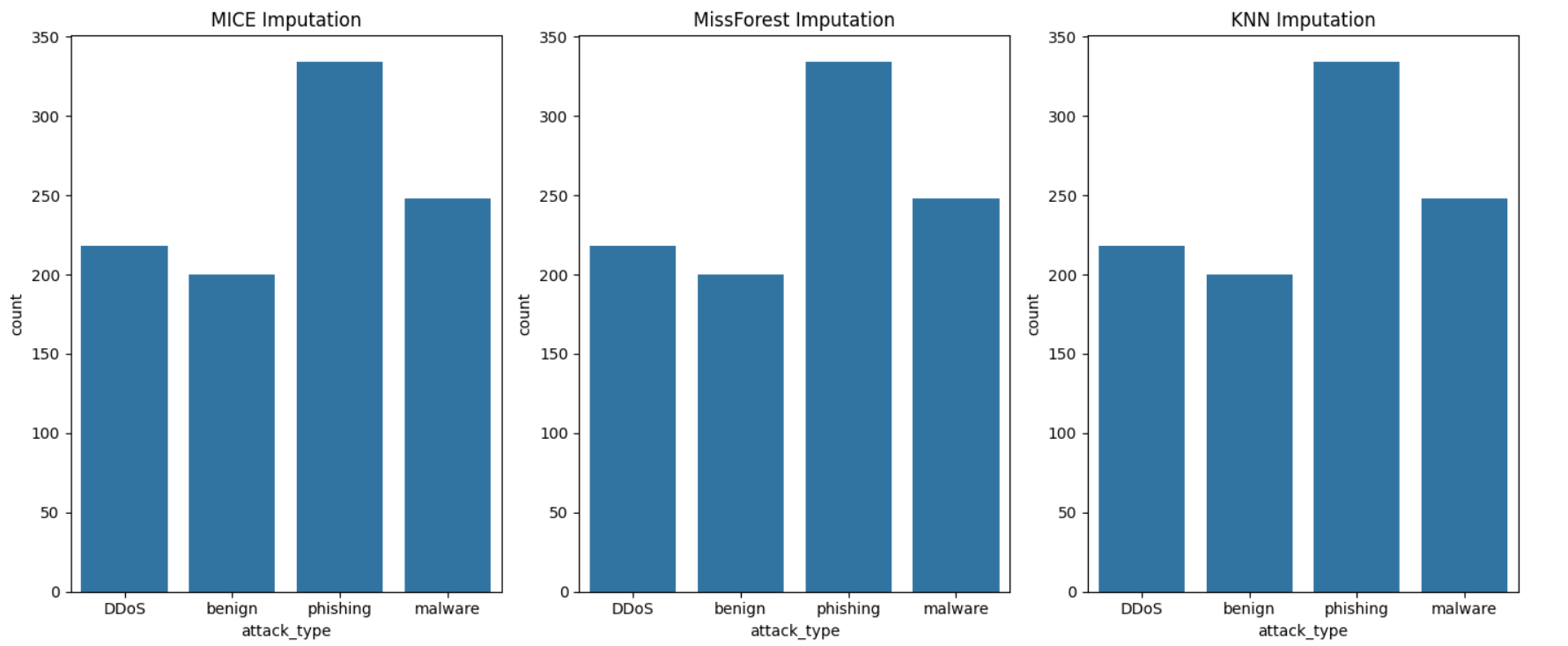
MICE, MissForest, and KNN Imputation: Each imputation method consistently maintains the distribution of
attack_type, with "phishing" being the most prevalent, followed by "DDoS" and "malware."
Conclusion
In cybersecurity, where data integrity and accuracy directly impact the effectiveness of defense mechanisms, handling missing data is not a trivial task. Advanced imputation methods, including multiple imputation, MissForest, MICE, Bayesian networks, and deep learning models, powerfully maintain or even enhance the performance of security models when dealing with incomplete data.
As cyber threats become increasingly sophisticated, the ability to handle missing data effectively will play a crucial role in the resilience of cybersecurity systems. By adopting advanced imputation techniques, cybersecurity professionals can ensure that their models remain robust and reliable, even in the most challenging data environments.
How prepared is your cybersecurity infrastructure to handle missing data in real-time scenarios?