

Working with Noisy Data in Cybersecurity: Advanced Techniques for Cleaning, Preprocessing and Handling Imbalanced Data
DataScience CyberSecurity - #0008

In the world of cybersecurity, data is abundant, but not all of it is useful. Raw data often contains noise—irrelevant, misleading, or incorrect information—that can obscure important patterns and insights. As cybersecurity increasingly depends on machine learning and data analytics, cleaning and preprocessing noisy data becomes an essential task. Whether the goal is anomaly detection, building intrusion detection systems (IDS), or threat classification, the quality of your data directly impacts the effectiveness of your security models.
What is Noisy Data?
Noisy data refers to information that is irrelevant or corrupt, making it difficult for systems to extract meaningful patterns. In the context of cybersecurity, noisy data might arise from:
Redundant logs: Repeated entries from systems or devices that don’t provide new insights.
Sensor errors: Log gaps or incomplete data due to malfunctioning hardware or logging software.
Inconsistent formats: Logs from different devices (e.g., routers, firewalls) that are not standardized, making aggregation challenging.
False positives/negatives: Alerts from intrusion detection systems that wrongly classify benign activity as malicious or vice versa.
These issues make it harder for analysts to identify real threats or patterns in the data, especially when working with large datasets.
Why Is Data Cleaning Crucial in Cybersecurity?
Cybersecurity data cleaning is essential for several reasons:
Improves Accuracy: Clean, high-quality data ensures that your machine learning models or detection systems can accurately differentiate between benign and malicious activities.
Reduces False Positives/Negatives: Preprocessing data effectively can reduce the occurrence of false alerts, making cybersecurity systems more efficient and trustworthy.
Speeds Up Detection: Data cleaning helps streamline analysis, allowing cybersecurity teams to detect and respond to incidents faster.
Event correlation: Logs with inconsistent timestamps or missing information make it difficult to correlate events across systems, which is critical for detecting coordinated attacks.
Enhances Model Performance: Machine learning models benefit significantly from well-preprocessed data, yielding better predictions and more actionable insights.
Types of Noise in Cybersecurity Data
Common sources of noise in cybersecurity data include:
Inconsistent Timestamps: Data from multiple sources can have different time zones or formats, making event correlation difficult. Logs need to be aligned to a common format, such as UTC.
High Dimensionality: Network logs may contain hundreds of features, some of which may be irrelevant for detecting specific attacks, leading to noise in the dataset.
Duplicate or Redundant Logs: Logs from firewalls, routers, and IDS systems might contain redundant information that needs to be filtered.
Outliers: Outliers in the data might be rare but benign occurrences or indicators of suspicious activity, and require careful analysis.
Advanced Noise and Data Cleaning Challenges in Cybersecurity
In more advanced cybersecurity scenarios, the nature of noise can become more complex. Some challenges that require advanced cleaning techniques include:
Multisource Data Fusion: Logs and events might come from multiple sources such as firewalls, routers, and IDS systems, each with its own format and time reference.
Event Correlation Across Systems: Many attacks only reveal themselves when correlated across multiple systems (e.g., a series of failed login attempts followed by suspicious network traffic). Ensuring that these logs are synchronized and standardized is crucial.
High Dimensionality: Cybersecurity datasets, especially those derived from network logs, can contain hundreds or even thousands of features. Not all features are relevant to the task at hand, so dimensionality reduction techniques may be necessary.
Techniques for Data Cleaning and Preprocessing
To clean noisy cybersecurity data, more advanced techniques can be employed, including:
Event Time Alignment and Window Synchronization: One of the first steps in data cleaning is aligning event timestamps across different systems. Timestamps from various logs may have inconsistencies due to different time zones or formats, making it difficult to correlate related events.

Handling Missing and Inconsistent Data: Missing data in cybersecurity is a common issue. Logs might have gaps due to hardware failures, network outages, or system misconfigurations. Techniques like forward/backward filling can help handle time-series data gaps.

Noise Reduction Using Feature Selection and Dimensionality Reduction: High-dimensional data is often noisy, and not all features are relevant for detecting threats. Principal Component Analysis (PCA) is an effective technique for reducing dimensionality while preserving the most critical features.

Outlier Detection for Anomaly Detection: Outliers in cybersecurity data, such as abnormal network traffic, can indicate malicious behavior or simple noise. Isolation Forest is a powerful anomaly detection technique for identifying and filtering out these outliers.

Feature Engineering for Cybersecurity-Specific Data: Feature engineering allows you to create new, more meaningful features based on the raw data. In cybersecurity, this might include aggregating the number of failed login attempts within a certain time window to detect brute-force attacks.
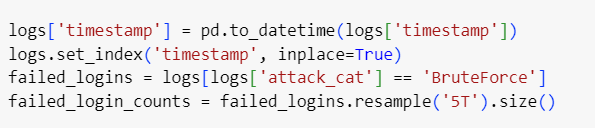
Step-by-step Implementation
The UNSW-NB15 dataset is a popular benchmark dataset for network intrusion detection research, designed to represent real-world traffic, including both normal and malicious behavior. However, the raw dataset often contains noise, missing values, and is heavily imbalanced, making it crucial to preprocess the data before building effective detection models.
In this guide, we'll discuss key techniques to clean, preprocess, and balance the UNSW-NB15 dataset.
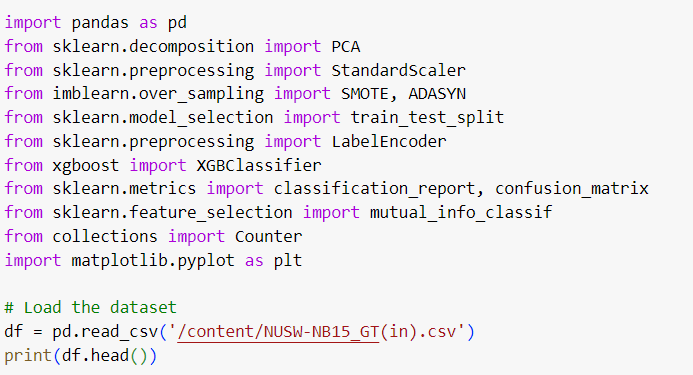
Step 1: Cleaning and Preprocessing the Data
1.1. Handling Missing Data
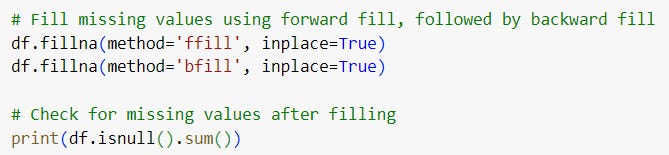
Missing data is a frequent issue in cybersecurity datasets. In the UNSW-NB15 dataset, certain fields such as attack references or source/destination ports may be incomplete. A simple yet effective approach to handle missing data is using forward and backward filling.
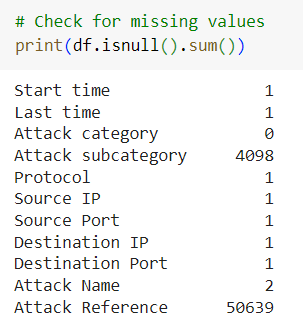
The dataset has some missing values in specific columns, such as Attack subcategory and Attack Reference.
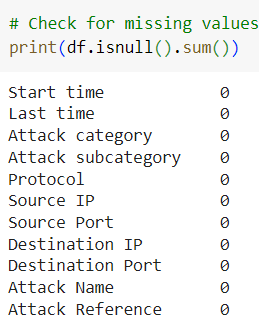
1.2. Removing Duplicate Records
Duplicates are common in network logs, especially when the same event is recorded by different monitoring systems. Identifying and removing these duplicates is essential for clean data.
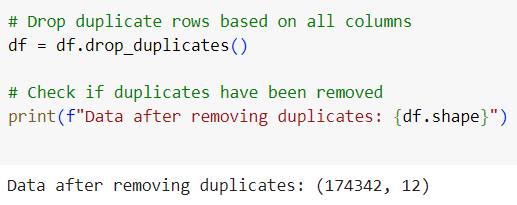
This reduces the noise from redundant entries in the dataset.
1.3. Standardizing Timestamps
In cybersecurity, logs from different systems may use different timestamp formats or time zones. Standardizing timestamps to a common format, such as UTC, is crucial for correlating events across systems.
This ensures that all timestamps are consistent, enabling accurate event correlation.
Step 2: Feature Engineering and Dimensionality Reduction
2.1. Feature Engineering
To make the data more useful for machine learning models, we can create additional features. For example, we can calculate the duration of each connection by subtracting the "Start time" from the "Last time" of each record.

The timestamps in Start time and Last time are converted to a readable datetime format and standardized to UTC. A new feature, Duration, is calculated by subtracting Start time from Last time. This feature reflects the connection duration in seconds, which could be useful for identifying patterns in network traffic.
2.2. Dimensionality Reduction Using PCA
The dataset contains numerous features, but not all of them may be relevant to detecting attacks. Principal Component Analysis (PCA) can be used to reduce the dimensionality of the data while preserving the most important information.
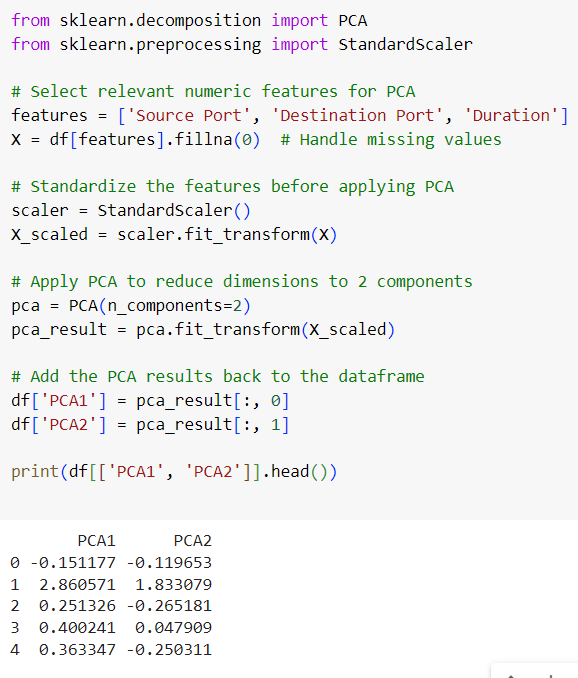
Three numeric features (Source Port, Destination Port, Duration) are scaled, and PCA reduces them to two principal components (PCA1 and PCA2).
This reduces noise from irrelevant features, allowing the model to focus on the most critical data points.
Step 3: Handling Imbalanced Data
One of the biggest challenges in the UNSW-NB15 dataset is the class imbalance between normal traffic and attacksn Imbalance can cause machine learning models to become biased toward the majority class, resulting in poor detection of minority-class attacks
Techniques to Handle Imbalanced Data:
Oversampling the Minority Class (e.g., SMOTE): Synthetic Minority Over-sampling Technique (SMOTE) generates synthetic samples to balance the classes.

The output of Counter(y) shows the class distribution in your dataset. Based on this, you can see that the smallest class, represented by '.', has only 1 sample, and there are multiple variations of similar labels (e.g., ' Fuzzers ' and 'Fuzzers', ' Shellcode ' and 'Shellcode'). This could be contributing to the issue, and label cleaning might be necessary before applying SMOTE.
Handle classes with very few samples: The class '.' has only 1 sample, which will cause issues with SMOTE. SMOTE cannot oversample a class with fewer than 2 samples when k_neighbors=1. You can either:
Remove this class from your dataset if it's not meaningful or too small to generalize.

Determine k_neighbors: After cleaning up the labels and addressing classes with very few samples, you can now determine the appropriate k_neighbors for SMOTE. For the minority classes like 'Worms' (169 samples) or 'Shellcode' (223 samples), you could use a smaller k_neighbors value, such as 2 or 3.


To control over how much each class is oversampled, you can pass a dictionary specifying the desired number of samples for each class

This gives you full control over how the classes are balanced, allowing you to avoid oversampling some classes to very large sizes if it's unnecessary.
Correlation-Based Feature Selection: Instead of relying on simple dimensionality reduction, introduce more complex techniques like correlation analysis or mutual information to understand the relationships between features.

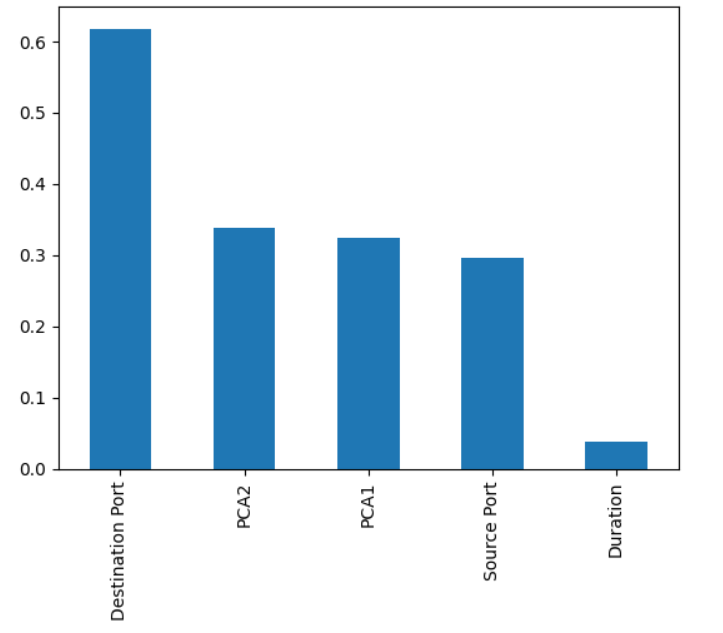
This helps to identify which features contribute the most to distinguishing between attack categories.

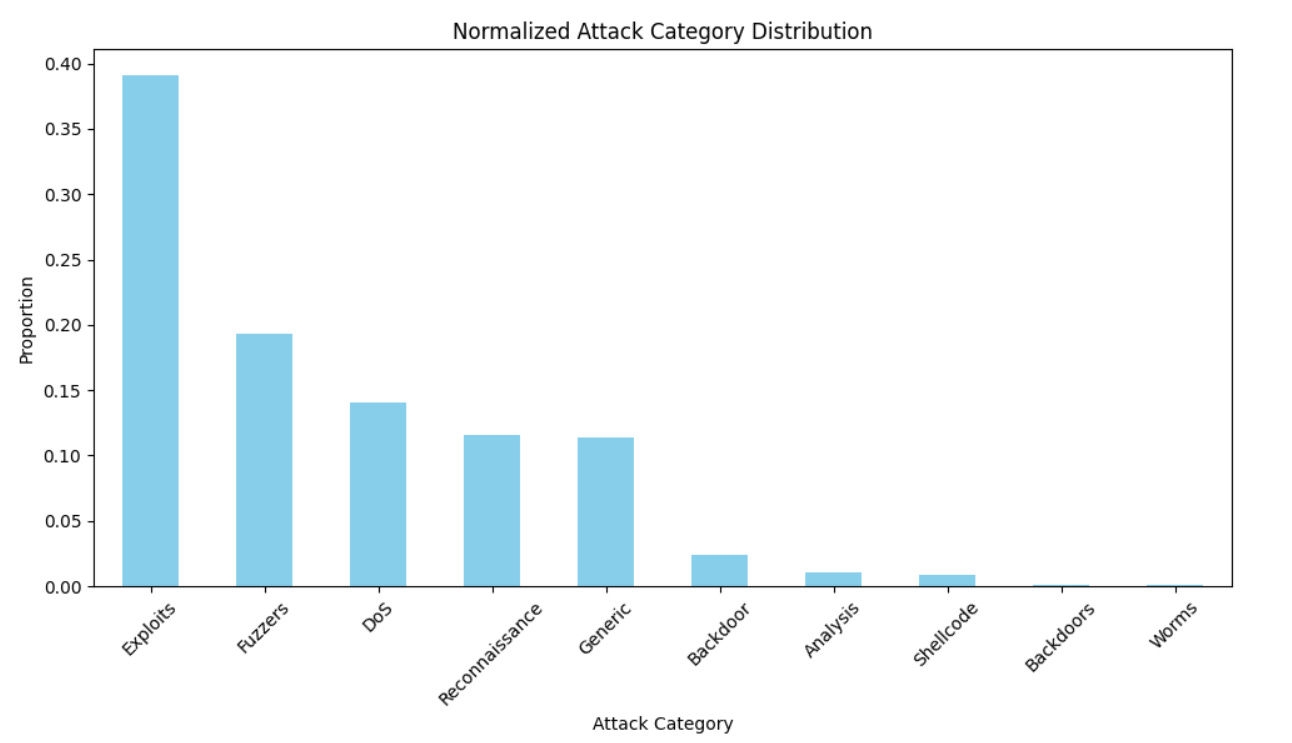
Step 4: Model Training

After cleaning and encoding the dataset, XGBoost is used to classify attack categories. The model accounts for the class imbalance by adjusting its internal weighting mechanism (scale_pos_weight). The model achieves high accuracy, particularly for larger classes like Exploits, Fuzzers, and DoS.
Step 5: Model Evaluation

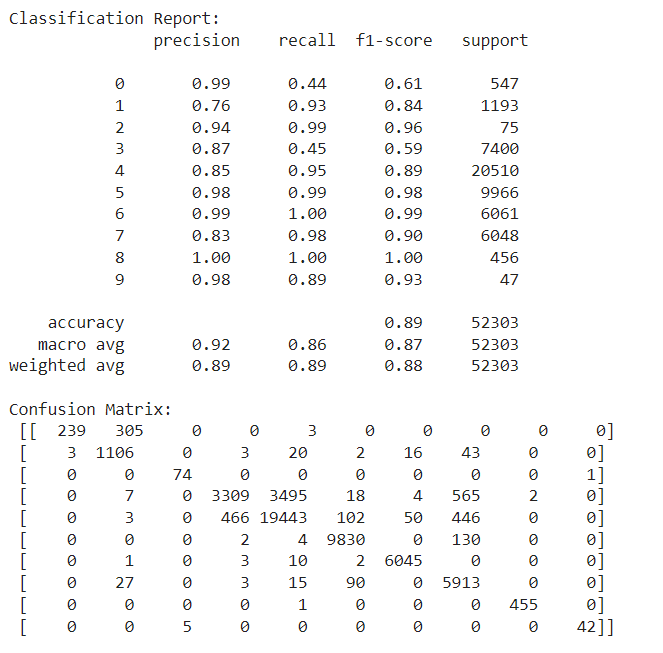
The model's performance is evaluated using precision, recall, and F1-score. The classification report shows that the model performs well overall, with a weighted accuracy of 89%. The confusion matrix indicates that most misclassifications occur in smaller classes or between closely related categories.
Conclusion
Handling noisy and imbalanced data is essential in cybersecurity for building accurate and reliable models. In this blog, we explored advanced techniques such as handling missing values, deduplication, timestamp standardization, and dimensionality reduction using PCA. These techniques help streamline the data, reduce noise, and improve the accuracy of machine learning models.
We also addressed class imbalance, common in datasets like UNSW-NB15, using methods like SMOTE and XGBoost's scale_pos_weight to enhance the detection of minority-class attacks. By implementing these techniques, cybersecurity professionals can significantly improve the performance of intrusion detection systems (IDS), making them more effective at identifying real threats while reducing false positives.
Mastering these data preprocessing methods is critical for leveraging machine learning to stay ahead of ever-evolving cyber threats.